DXトレンド⑦ ― データ分析 ―

テク仁(えんまん七福仁 IT技術担当)のつぶやき – その7
EnMan社にてCTOを勤めさせて頂いている石井慎一郎です。
EnMan社が、一流IT企業との開発・PMO連携、サービス事業提供、更なるアジア圏ビジネス隆盛を目指す中で、その背景にある昨今のIT技術やシステム動向について徒然なるままに認めます。
DXトレンドにおいて、データ分析による知見の可視化が大きなインパクトとなっていることは、このコラムの冒頭でも述べました。
改めて、このデータ分析について採り上げてみましょう。
■データ分析の導入が進んでいる背景
ECサイトに会員登録して商品を購入すると「個人情報」「購入した商品の履歴」「過去に閲覧したページ」などの情報が蓄積されることになり、かつ、このデータ量は日々増え続けています。それらを活用して、各種ネット販売サービスにおいては、「おすすめ商品」や購入者が興味を持ちそうな商品の一覧が表示されたりもしています。
これなどは、まさにデータ分析によって実現されているわけです。
このようにデータ分析による様々なサービス向上を実現した背景には、以下のような幾つかの事象があります。
→取得されるデータの多様化と増加
従来、利用者の登録情報や販売履歴情報程度しかなかったデータが、現在は、スマホ等の普及により、移動・位置データ、健康(生体情報)データ、スケジュールデータなど、圧倒的に増えています。つまり、何かを予測する際に活用できるデータの種類が増えており、その精度向上に寄与していると言えるのです。
→データの結合技術の進展
あるアプリにログインする際に、GAFAのID/Passwordでログインが出来るような場面に遭遇したことがありませんか?
利用者は、別々のアプリで購入したりしていた積りでも、データとしてはそれぞれが結合して、より利用者の行動を一貫して認識できるようになるわけです。
→統計処理に強い言語の登場
最近、よく耳にする言語のPythonにはNumPyなど、データ分析関連のライブラリが実装されています。また、統計解析向けのプログラミング言語Rも登場してきています。
■データ分析作業とは?
簡単に言ってしまうと、あるデータ(の塊)に対して、何らかの傾向を見出すことになります。その結果、今後の予想に繋げることになります。
様々なビジネスデータに分析に当たっては、まずは従来の業務分析における分析対象領域のデータを収集して理解することから始まります。その上で、以下のような流れで作業を進めることになります。
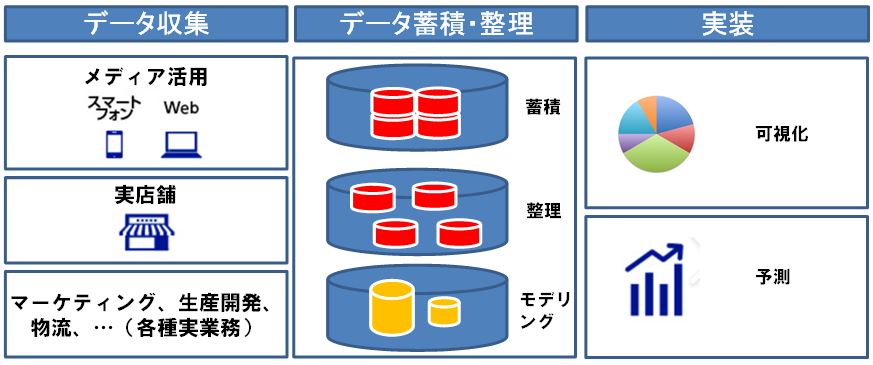
→データ蓄積・整理
入力ミスがそのまま残っていたり、未入力のデータによる値の欠損があったりした場合に、分析精度が悪化するリスクが発生します。そのために、欠損値や不正な値を他の値に置き換えたり、分析に適した形式にデータを再構成したりと、さまざまな加工を行う必要があります。
→モデリング
データ分析や統計の手法を用いて、特定の入力データから予想を導き出すプログラム(モデル)を作成する作業です。
ここでは、統計学の様々な概念や手法を用いる必要があります。上記のデータ整理を含めて、行ったり来たり、試行錯誤が繰り返される作業となります。
→効果検証と実装
データ分析の結果として得られた内容が、どれほどビジネスに貢献するのかの検証を行い、採用可否を決定します。採用が決まったら、作成したモデルをサービスへ実装していきます。
なお、世の中の流行やサービス利用者の行動が変われば、データ自体が変わり、適切なモデルも変化します。よって、データの傾向をふまえながら、継続的にモデル作成~サービス実装を繰り返す必要があります。
■データ分析における概念を幾つか…
モデリングにおいて、各種データ分析や統計での概念を使用すると書きました。ここで、その全てをご紹介は出来ませんが、用語として知っておきたいものを幾つかピックアップしておきます。
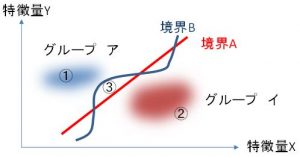
→分類:あるデータがどの集団に属するかを予測すること。
スコアリングや確率推定によって、そのデータがある集団に属する確率やスコアを算出して代替することもあります。
→回帰:あるデータにおいて、何らかの属性となる変数の数値を予測すること。
例えば、あるデータと似通ったデータを探し出して、更にその変数の動向を分析することによって予測することになります。
つまり、ある利用者について、ある商品を今後、どの程度購入するかを予測する際、その利用者と類似性のある他の利用者の過去も含めた購入履歴を集めて予測するなどの利用例が考えられます。
→汎化とオーバーフィッティング
あるデータの集まりにおいてパターンが発見できた場合、そのパターンが未知のデータに対しても適用可能であることが重要です。これは汎化できるパターンと呼びます。一方、そのデータで偶然起きているだけのパターンについては、データのオーバーフィッティングと呼び、データ分析において回避すべき重要な概念になっています。
ぞの他、特定の基準でグルーピングするクラスタリング、データの典型的な振る舞いを明らかにするプロファイリングなどなど、触れたい項目は山積です。また、それぞれに数学的な説明の解説もあるわけで、数式アレルギーのある方は、なかなかとっつき難いのですが、興味のある方は、様々な書籍も最近は出ていますのでご覧になっていただければと存じます。
■データアナリスト
このようにデータ分析という作業は、ビジネスの世界でも確立されてきている分野になります。そのため、データ分析に役立つ資格・検定も出てきています。
IPAが定めるITSS+では、データサイエンス領域が新たに加えられており、その手順やスキルチェックリストなども規定されています。
(ITSS+(プラス)・ITスキル標準(ITSS)・情報システムユーザースキル標準(UISS)関連情報:IPA 独立行政法人 情報処理推進機構)
また、統計検定、G検定など、様々な検定資格も出てきています。
所謂、従来はITの専門家という観点では、システム開発を専門に行うシステムエンジニアやプロジェクトマネージャーが中心に置かれていましたが、DXが盛んになってきている現在では、新たな職種も生れてきており、かつその専門性を強みとしたビジネスも生まれてきていると言えます。
データ分析に対するビジネスのニーズはますます高まっていることから、この領域でのキャリアパスも含めた人材育成についても実践を通じて整理しておきたいところになってきています。
この記事の執筆者

石井 慎一郎
1984年 東京大学卒、日本電気㈱入社
ソフトウェア開発研究部門 配属(18年) 、金融システム開発、SI部門(13年)、グローバルビジネス推進部門(CTO)(3年)
時代の最新ソフトウェア・アーキテクチャの研究開発経験を礎に、ビジネスの最前線への適用、大規模SIでの顧客対応、最新技術プロダクトのグローバル展開を行った貴重な経験を持つ。
2018年末 日本電気㈱退職。個人事業主にてIT領域で企画・開発支援等、幅広く活動。
2020年7月~ EnMan Corporation 取締役CTO